Background:
Architecture and Engineering are two terms often used to describe IT roles. In 2002, I was fortunate enough to work on a large Enterprise project using Spewak’s methodology. Prior to that project, I worked on many financial data related projects and intuitively was able to properly organize the data for maximum flexibility. My success with data was well enough known that other areas reached out to understand my approach. The Enterprise project in 2002 provided a methodology that aligned with what I had been doing intuitively, Since then, I’ve adapted the methodology for many different projects. It really didn’t matter the type of project (e.g. Configuration Management, Customer Enrollment, Eligibility) the methodology proved to be a pragmatic way to create an Architecture for the project. Projects always had two key components, business process and data required to support the business process.
From the forward to Spewak’s book: Enterprise Architecture Planning: Developing a Blueprint for Data, Applications And Technology :
“As I was reading this book for the first time, I was occasionally skeptical about a particular methodological point. However, in every instance, before I had read to the end of the chapter, I was convinced that the innovative and pragmatic approach to accomplish the purpose was sound.” – John A. Zachman
My website, Above The Line It is about looking at IT solutions from a business perspective. The focus is to create a logical architecture along with clearly defining business data. Hopefully, over a series of posts I’ll be able to outline a methodology for a logical architecture that aligns with current applications of technology. The first step is to define the Architecture or more specifically a Logical Architecture for IT.
Architecture Definitions:
Architecture is described by Encyclopedia Britannica as:
“the art and technique of designing and building, as distinguished from the skills associated with construction. The practice of architecture is employed to fulfill both practical and expressive requirements, and thus it serves both utilitarian and aesthetic ends”
For the IT Architecture role, Gartner Architecture Glossary provides their definition of Architecture as:
- In reference to computers, software or networks, the overall design of a computing system and the logical and physical interrelationships between its components. The architecture specifies the hardware, software, access methods and protocols used throughout the system.
- A framework and set of guidelines to build new systems. IT architecture is a series of principles, guidelines or rules used by an enterprise to direct the process of acquiring, building, modifying and interfacing IT resources throughout the enterprise. These resources can include equipment, software, communications, development methodologies, modeling tools and organizational structures.
Britannica clearly separates Architecture from construction and implies Architecture is a combination of Art (expressive) and Science (utilitarian). Gartner mentions ‘logical’ a single time with the rest of the definition focusing on the orchestration of the technical aspects of the architecture (i.e. construction). A more robust Architecture definition requires aspects of both the logical aspects of Britannica’s definition and the technical aspects referenced by Gartner. The Logical Architecture does not require any specific technology in the initial steps of defining the architecture.
Technical considerations apply to a Logical Architecture similarly to how engineering guidelines apply to an Architecture designing a house. The Architect is aware of engineering guidelines to build. Those only serve to guide the architecture. The decision to use a laminated bean or a steel beam for support has little impact on the overall architecture of the house.
Logical Architecture Methodology:
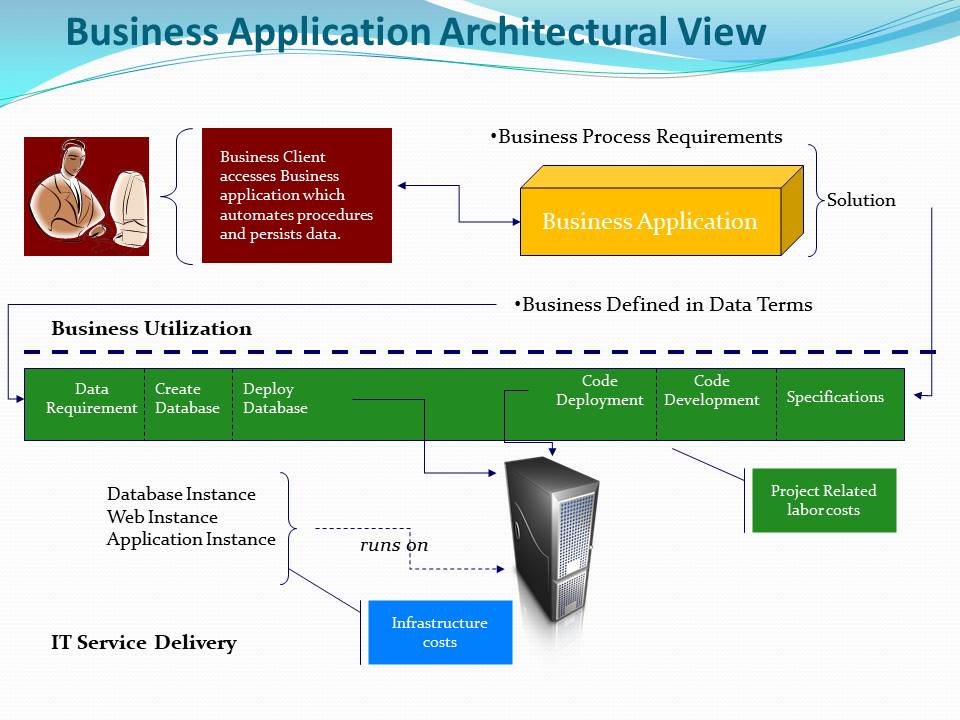
The four pillars of creating a robust Architecture are Business Architecture, Data Architecture, Solution Architecture and Technical Architecture. The below briefly defines each pillar and how they relate to your final Solution Architecture used to construct a Business Application.
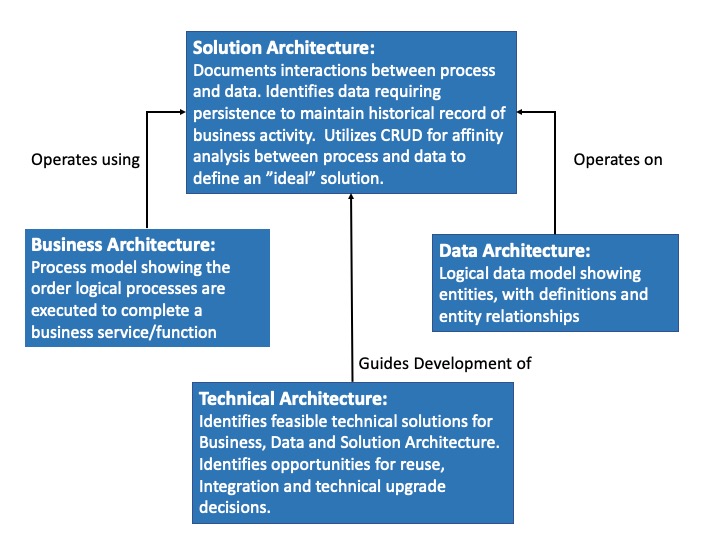
Logical Architecture starts with the business. The methodology consists of business process and data modeling. As you build out the business process model, it’s important to understand the data (data entities) that each business process uses. This will help organize business processes and data into a recommended Solution Architecture. Technical Architecture guidelines are used to construct the Business Application from the logical Solution Architecture.
Where to begin?
Start by putting the business first. On occasion you hear “IT Drives the Business”. I prefer to take the perspective of “IT Accelerates the Business”. The former puts IT first while implying newer technology improves business outcomes. The latter embraces the business to improve the current state and accelerate business critical decisions, improve response time to the market, or flexibility to deliver new services to the market.
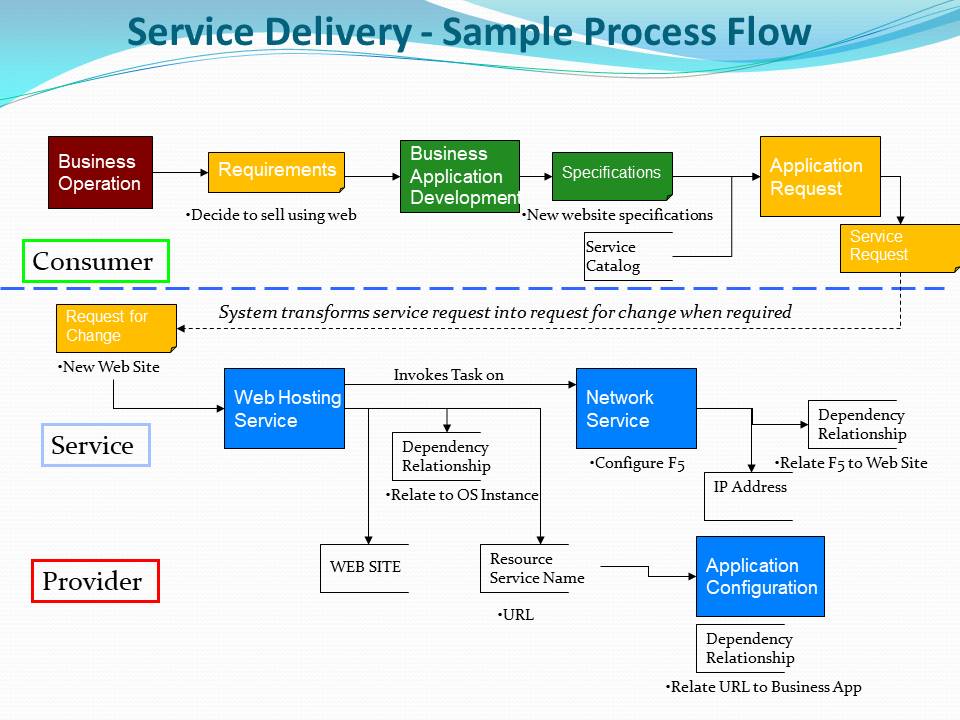
Another aspect is you do not need to start by exhaustively deconstructing all the existing business applications currently used to run the business. This is expensive and time consuming process that is not repeatable. Rather take the approach of documenting business in terms of the business processes and key data concepts developing a deep understanding of the business. The entails documenting the logic and semantics of the business. Taking this approach defines solutions within the business context. At this point, you can inventory you current business applications and organize them by your IT Logical Architecture.
You can begin to lay out your architecture project by first taking into account that businesses have a natural “left to right” flow of processes and critical data components. Take the example of starting a new business. Most likely, it starts with an idea for a product or service (i.e. Product Development). The next step is to identify a target customer (i.e. Market Research) and hopefully you’ve been able to sell the product (i.e. Sales). This quickly defines business processes requiring further analysis. It’s also apparent how data relates to each process. This helps define foundational data for your business: Product, Customer, Sold Product which can be modeled.
Enterprise Architecture can conjure up visions of expensive, long running projects without achieving the promised benefit to the business. In some cases, Enterprise Architecture is described a big E and little e. As with anything, the larger the project the more risk for failure. Instead of Big E and little e, start thinking in terms of context. Logically looking at the sample business below shows three “contexts” to use for continued analysis. The contexts created are Product Development, Market Research and Sales. This allows project planning to define the effort in manageable pieces. Below is a sample notation used to visually depict the new business outlined. The shaded boxes are the high level business process, the lines indicate data flow and the open boxes depict data entities. The data entities depicted on the process model relate back to enterprise logical data model.

Immediately, three focus areas are identified along with the foundational data required to run the business. Market Research is taking the customer characteristics you plan to target and applying it to the universe of customers. The output (i.e. data) is Customer. Product development is defining the products planned for those customers. Sales would contact Customers identified from Market Research and hopefully sell the Products. The output again is data, Customer Product.
A close relationship between process and the data created by the process provides the context to develop your Solution Architecture. It’s at this point you can start to apply your technology best practices to create a target solution architecture. Understanding the process that creates each type of data begins to layout your data domains. For example, Market Research creates the Customer data. A best practice is to make this your company’s source of truth for Customer data.
Thinking ahead to a Market Research implementation, Market Research needs data services for all the actions required to maintain a Customer. This includes managing unique Customers along with data about Customers. The initial view is that all customers are created and maintained by Market Research. Reality is this is one source of Customer creation. Over time Customers can be identified via referrals, customer initiated or through sales contacts. Each one of these have the same data management needs to create, maintain and update Customer data that Market Research has. The scope of the solution should consider having Market Research develop a robust set of customer data services to share across the enterprise. These data services can then be presented via a variety of mechanisms for input.
Recommendation:
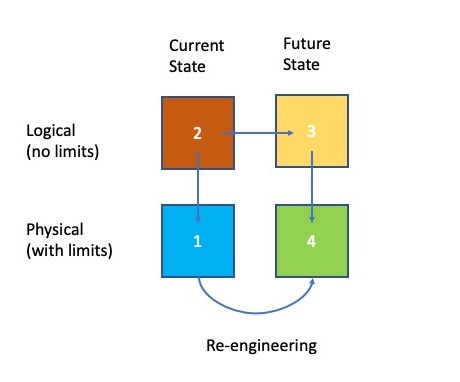
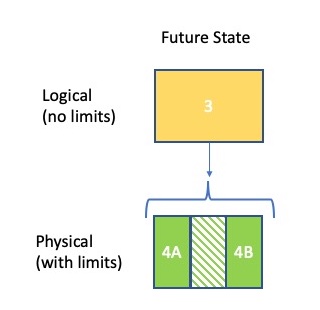
Before embarking on a effort to upgrade existing systems or purchase a vendor product, take the time to create a Logical Architecture of your business. A logical architecture is independent of any current implementations and can be used to evaluate how well current implementations meet business requirements.
A logical view creates a business context for evaluating current implementations and vendor solutions. Opportunities for data sharing and consolidation of applications is more obvious. Starting Above the Line IT, avoids the trap of re-engineering existing implementations with an expectation of getting better results for the business.
See my post discussing the difference between Architecture and Re-Engineering.